Connect your ChatGPT Assistant to your SQL Database

7 days ago OpenAI released ChatGPT assistants, and with that destroyed 9,000 companies providing little to no value on top of ChatGPT, leaving only the serious software vendors standing - Such as us, providing actual value on top of OpenAI and ChatGPT.
8 days ago you could hire a marketing genius, pay a developer to create 50 lines of JavaScript and 70 lines of PHP, and trick half the "get rich fast with BitCoin idiots" to buy into your scam. After OpenAI released assistants this is no longer possible. The result being that only the serious software vendors are left standing, such as us for instance.
For obvious reasons we celebrated on that day 🥳
Anyways, I am going sideways here - Let's get on with the subject of this article, which is how to create a ChatGPT assistant or GPT and connect it to your SQL database ...
Connecting your GPT Assistant to SQL
The most important feature OpenAI released was the ability to connect your ChatGPT assistant to your own API. This allows you to expose an API to ChatGPT, and have ChatGPT consume your API to do all sorts of interesting stuff. To understand what I mean try the following assistant and click the "What's Mandy's phone number" conversation starter.
The above assistant is basically connecting to one of our Magic Cloudlets, which has wrapped a database into an endpoint, allowing us to create a ChatGPT agent that queries an internal SQL database in our cloudlet. The phone number and email address below was fetched from this database. Below you can see a screenshot of it in action.
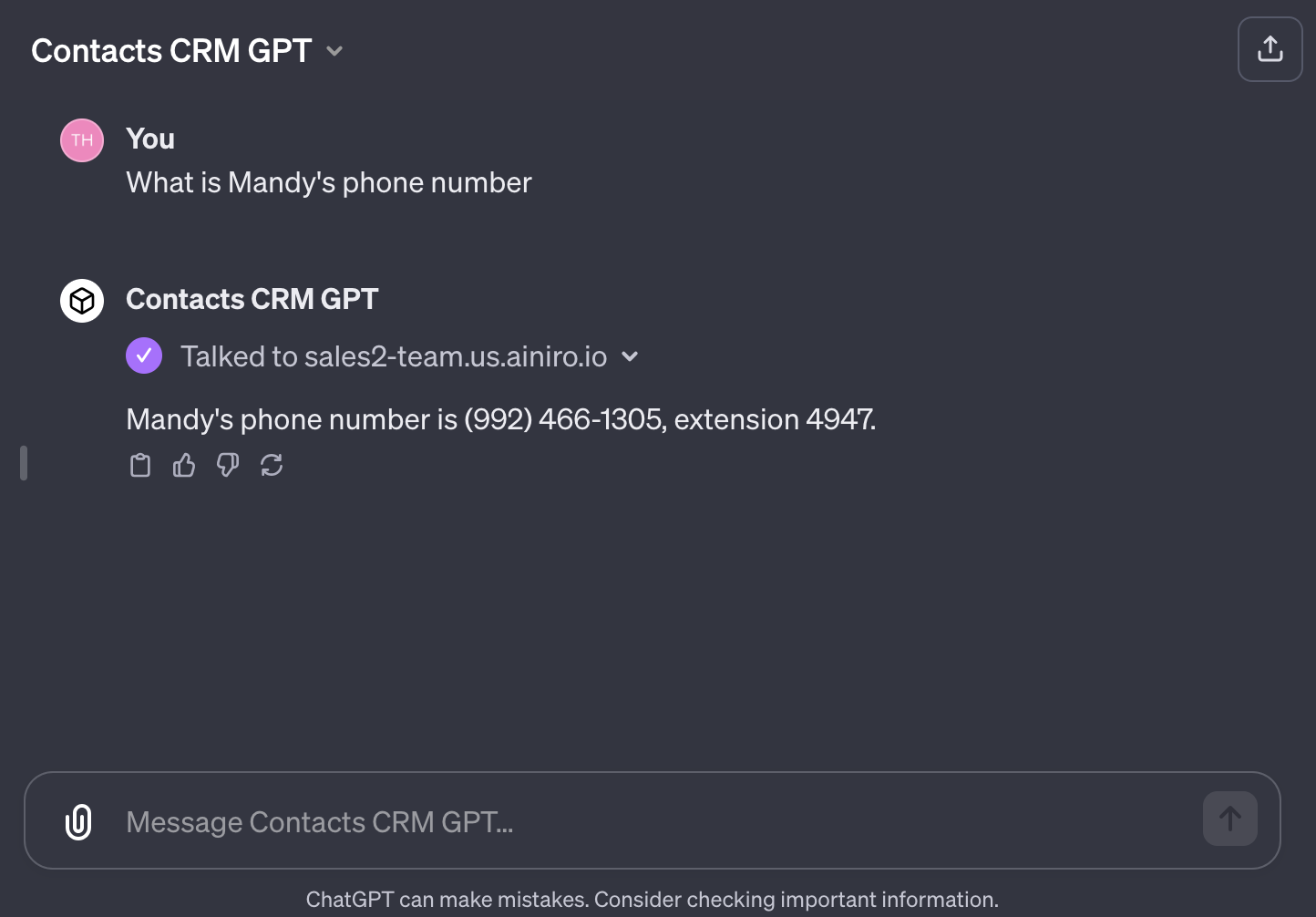
The use cases for something like this is almost science fiction, allowing us to create AI based software, completely replacing existing UI and UX with things such as AI-based chatbot interfaces, voice recognition, speech synthesis, and any amount of complexity - Integrating with any system you might have from before. And with Magic and Hyperlambda creating such integrations is almost as easy as clicking a button.
I created the API endpoint live in 12 minutes in a YouTube video, from scratch - Something you can see in the following video. I apologise for spending so many minutes (12), but it was the first time I actually played around with GPT assistants, so it took me some while to understand how to create them 😁
My guess is if you started out with PHP or Python, you'd spend half a week before being able to reproduce what I did. Not because I'm such a smart guy, but because we've got Magic and Hyperlambda.
Implementation
First I created my own SQLite database with SQL Studio from scratch with 3 columns:
- name
- phone
It looks like the following.
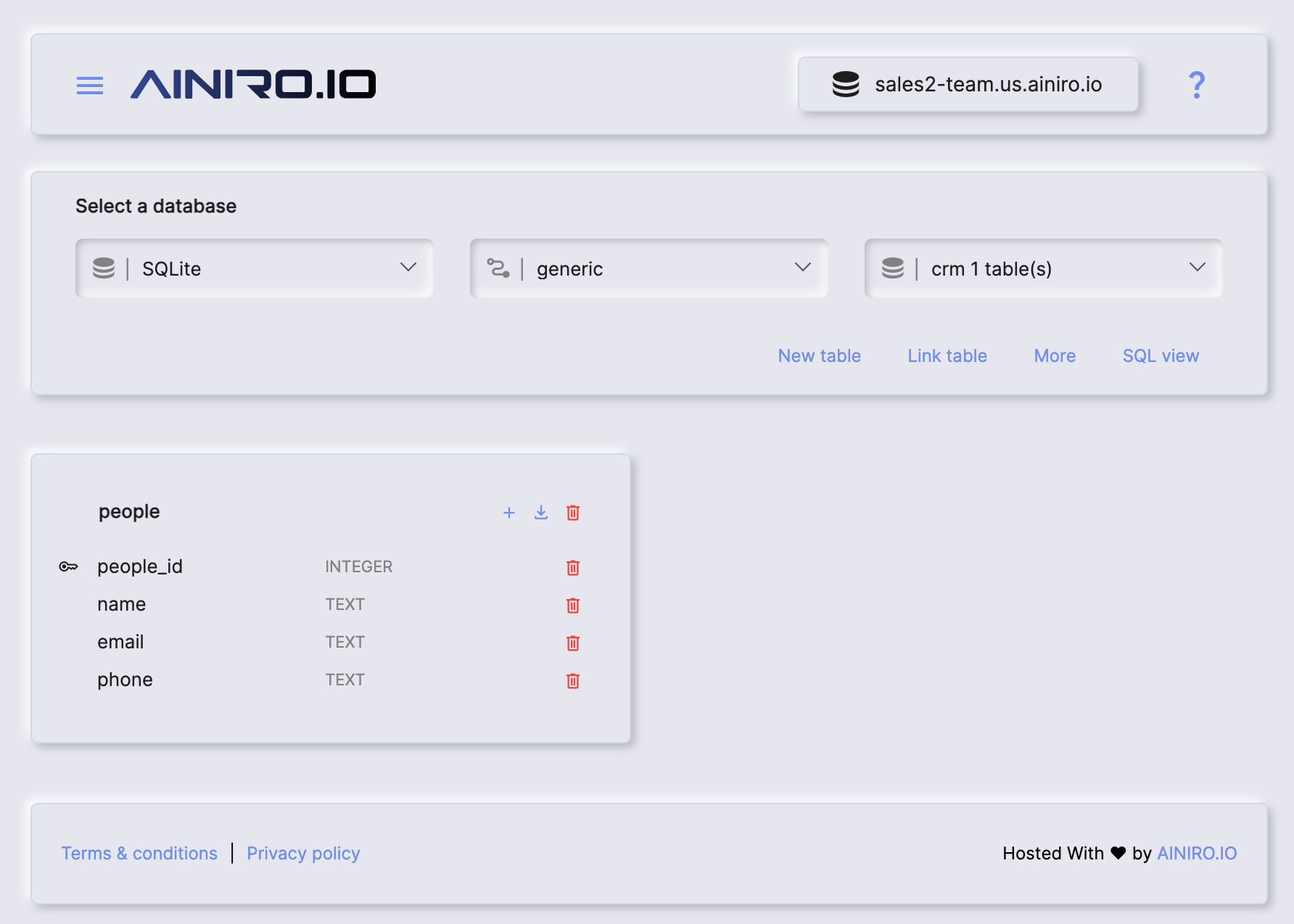
If you just want a rapid method to create the database you can do so with the following SQL DDL schema. However, I encourage you to watch the above YouTube video for more details about the implementation.
CREATE TABLE people(
people_id integer not null primary key autoincrement,
name text not null,
email text not null,
phone text not null
);
Notice, if you create the database with the above DDL, it won't show in your SQL Studio database designer due to caching. However, you don't really need to see the database, you just need to know it's there. Also notice you'll need to create the database first, something you can do in "Manage/Databases" by creating a new database called "crm".
Then I populated the database by doing a Google search for "CSV examples" and downloaded a CSV file with 100 random non-existent names, emails, and phone numbers. Afterwards I uploaded my CSV file and imported it into the database with the following Hyperlambda. You can find a download to the CSV file further down in the article, just remember to upload the file to your cloudlet before you try to import it.
io.file.load:/etc/people.csv
csv2lambda:x:-
data.connect:crm
for-each:x:@csv2lambda/*
data.execute:insert into people (name, email, phone) values (@name, @email, @phone)
@name:x:@.dp/#/*/name
@email:x:@.dp/#/*/email
@phone:x:@.dp/#/*/phone
When I was done with that I had an SQL database with example data I could use as a foundation for my API. You can download my CSV file below if you want to reproduce what I did.
To import the file you need to upload it to your "/etc/" folder in your cloudlet using for instance Hyper IDE.
Creating our API endpoint
Hyperlambda is super dynamic in nature. Fundamentally an HTTP endpoint is just a file resolved according to its path, executed once the endpoint is accessed. Create a new folder as "/modules/foo" and a new file inside this folder called "people.get.hl", and add the following content to it.
.arguments
name:string
data.connect:crm
data.select:select name, email, phone from people where name like @filter
@filter:x:@.arguments/*/name
return-nodes:x:-/*
You know have an endpoint taking a name, that will return the phone number and email address associated with your name. Now it's time to map things into a ChatGPT assistant. The only real complex part in this process is the OpenAPI specification, whieh should resemble the following.
{
"openapi": "3.1.0",
"info": {
"title": "Get contacts",
"description": "Get contact information from CRM",
"version": "v1.0.0"
},
"servers": [
{
"url": "https://XXX-YYY.us.ainiro.io"
}
],
"paths": {
"/magic/modules/foo/people": {
"get": {
"description": "Returns phone number and email given a name",
"operationId": "GetContactInfo",
"parameters": [
{
"name": "name",
"in": "query",
"description": "Name of contact you want to retreieve phone number and email for",
"required": true,
"schema": {
"type": "string"
}
}
],
"deprecated": false
}
}
},
"components": {
"schemas": {}
}
}
Give your GPT a name, save it, and share it with your friends and colleagues - And you've got an "AI application" exclusively using ChatGPT as its user interface.
So much for the "ReactJS is better than Angular" debate I guess 😉



