Natural Language API, a New Approach to AI

WTF you talking about bruh? 🤪
Let me explain. A "Natural Language API" is an HTTP endpoint that takes a single argument being "natural language" - AKA; English, Turkish, Swedish, or "Whatever". Then it uses that text input to generate code it then executes and returns the result from. Examples of input argument values can be for instance;
- "Scrape ainiro.io and return the first 3 external hyperlinks you find"
- "Fetch www.billion-air.org's robots.txt file and return its raw text value to me"
- "Return all URLs from ainiro.io's sitemap that does NOT contain '/blog/' in their URLs"
- "Scrape ainiro.io and return all paragraphs containing the word 'Hyperlambda'"
- "Skrape ainiro.io og returner tekst verdien av H1"
For the record, the last bugger upstairs was written in Norwegian to illustrate a couple of language points ... 😉
And of course, for kicks ...
- "Calculate the result of (2+2)x(5-1) and return to me"
- "Calculate 2+19 and return to me"
- "What's today's weekday?"
You see, all of the above prompts have been tested through our Natural Language API debugger, and actually works 100% perfectly, and does exactly as ordered. And for the record, each request executes in some 1 to 5 seconds. To understand "the value proposition", let's imagine the output from our last example.
{
"weekday": "Saturday"
}
Hmm, that is definitely not an LLM response is the first thing that should be obvious for you at this point, at which point you would be correct. You see, the above prompt; "What's today's weekday?" resulted in the following code being generated.
date.now
date.format:x:-
format:dddd
yield
weekday:x:@date.format
Then when the above code is executed, it results in the above JSON object. So let me explain the steps carefully for you here about what's happening.
- The API is invoked with natural language input
- Hyperlambda code is dynamically generated using the prompt as its input
- The Hyperlambda code is executed on the server, in-process
- The result of the execution is returned to the caller as JSON
Da fuck bruh! You dey craze?? 😳
At this point I suspect most of my senior dev head readers are a bit more than averagely sceptical, since an execution time of 1 to 5 seconds simply implies I'm doing this in-process, on the server. If you don't understand the problem, allow me to explain. You see, allowing AI to basically execute any arbitrary code it wants to, according to natural language instructions, potentially originating from Russian hackers, is probably the single largest existential security threat you've probably ever seen I presume in your entire life!
Actually ... 😉
NOT! You see, executing AI-generated Hyperlambda code is 100% safe, assuming you know what you're doing. Let me illustrate by showing you all the code from my HTTP endpoint.
/*
* HTTP GET endpoint taking natural language input, generating Hyperlambda code solving the problem,
* and returning the result of the execution to the caller. Response time 1 to 5 seconds typically.
*/
.arguments
instruction:string
/*
* System instruction.
*/
.sys:@"# Objective
You are a Hyperlambda software development assistant. Your task is to generate and respond with Hyperlambda.
DO NOT generate Hyperlambda that requires authentication or authorisation.
DO NOT generate Executable Hyperlambda files or HTTP endpoints unless user EXPLICITLY asks for it!
Make sure you always return the result of your invocation to the caller."
// Helper to log exception
.code
try
/*
* Invoking OpenAI with Hyperlambda Generator as model, and above instruction as our system instruction.
*/
execute:magic.workflows.actions.execute
name:openai-query
filename:/modules/openai/workflows/actions/openai-query.hl
arguments
model:"HYPERLAMBDA_GENERATOR_MODEL"
max_tokens:int:2500
temperature:decimal:0.0
query:x:@.arguments/*/instruction
instruction:x:@.sys
// Transforming result to a lambda object.
hyper2lambda:x:@execute/*/answer
set-value:x:@.code
get-value:x:@execute/*/answer
// Checking if user is root, at which point we just execute "whatever".
if
auth.ticket.in-role:root
.lambda
// Adding lambda object to [.lambda] invocation.
add:x:./*/.lambda
get-nodes:x:@hyper2lambda/*
// Executing lambda object, and returning the result.
.lambda
invoke:x:-
if
not-null:x:@invoke
.lambda
return:x:@invoke
return-nodes:x:@invoke/*
else
/*
* User is NOT root, so we execute the lambda object within a [whitelist],
* to avoid anonymous users from creating potential malicious code.
*
* None of the whitelisted slots changes state on the server, so worst case scenario,
* somebody might create a long lasting job, binding up a single thread and socket
* before returning, but that is literally the largest risk we've got with this solution,
* even though we're technically executing arbitrary Hyperlambda code, generated by an AI.
*/
// Adding lambda object to [whitelist] invocation.
add:x:./*/whitelist/*/.lambda
get-nodes:x:@hyper2lambda/*
// Executing lambda object, and returning the result.
whitelist
vocabulary
date.now
date.format
format
set-name
set-value
get-value
get-name
get-count
get-nodes
add
insert-after
insert-before
math.abs
math.add
math.ceil
math.cos
math.decrement
math.divide
math.floor
math.increment
math.max
math.min
math.modulo
math.multiply
math.random
math.round
math.sin
math.sqrt
math.subtract
strings.builder
strings.builder.append
strings.capitalize
strings.concat
strings.contains
strings.ends-with
strings.html-decode
strings.html-encode
strings.join
strings.length
strings.matches
strings.regex-replace
strings.replace
strings.replace-not-of
strings.split
strings.starts-with
strings.substring
strings.to-lower
strings.to-upper
strings.trim
strings.trim-end
strings.trim-start
strings.url-decode
strings.url-encode
response.headers.set
response.status.set
for-each
if
else-if
else
return
return-nodes
yield
vocabulary
html2lambda
html2markdown
lambda2html
markdown2html
xml2lambda
lambda2xml
json2lambda
lambda2json
http.get
and
or
eq
neq
not
mt
lt
mte
lte
get-name
null
not-null
exists
not-exists
unwrap
convert
.lambda
if
not-null:x:@whitelist
.lambda
return:x:@whitelist
return-nodes:x:@whitelist/*
.catch
log.error:Could not generate code
exception:x:@.arguments/*/message
code:x:@.code
throw:I am sorry but I cannot do that Dave
public:bool:true
status:int:400
The above ensures that unless you're me, you're basically restricted to executing only slots that does not in any ways change the state of the server. Worst case scenario, you might invoke a couple of "dubious HTTP GET requests", possibly even requests lasting for a couple of minutes too, but that would be the worst case scenario. And if people are abusing the [http.get] slot, I might end up turning off that bugger too, basically restricting you to mathematical operations and string crap.
However, the above little "meta programming trick", allows us to securely executing arbitrary code generated by an LLM without fear of security breaches, or accidentally executing malicious code.
The above is such a "big deal" I become a little bit wet in my eyes when I think about it. To understand the problem, realise that if for instance Microsoft, Google, or Lovable for that matter wants to do something similar, for security reasons they'll need to create some sort of virtual environment to securely execute AI-generated code, for then to just throw away that machine afterwards, since in theory the AI generated code might have installed malware during execution.
This implies execution times, even with Microsoft's super clusters would take somewhere between 2 to 10 minutes for an individual function of similar nature, unless they used Hyperlambda of course - While in Hyperlambda the total HTTP request time is typically a couple of seconds. Don't believe me? Check out the screenshot ... 😁
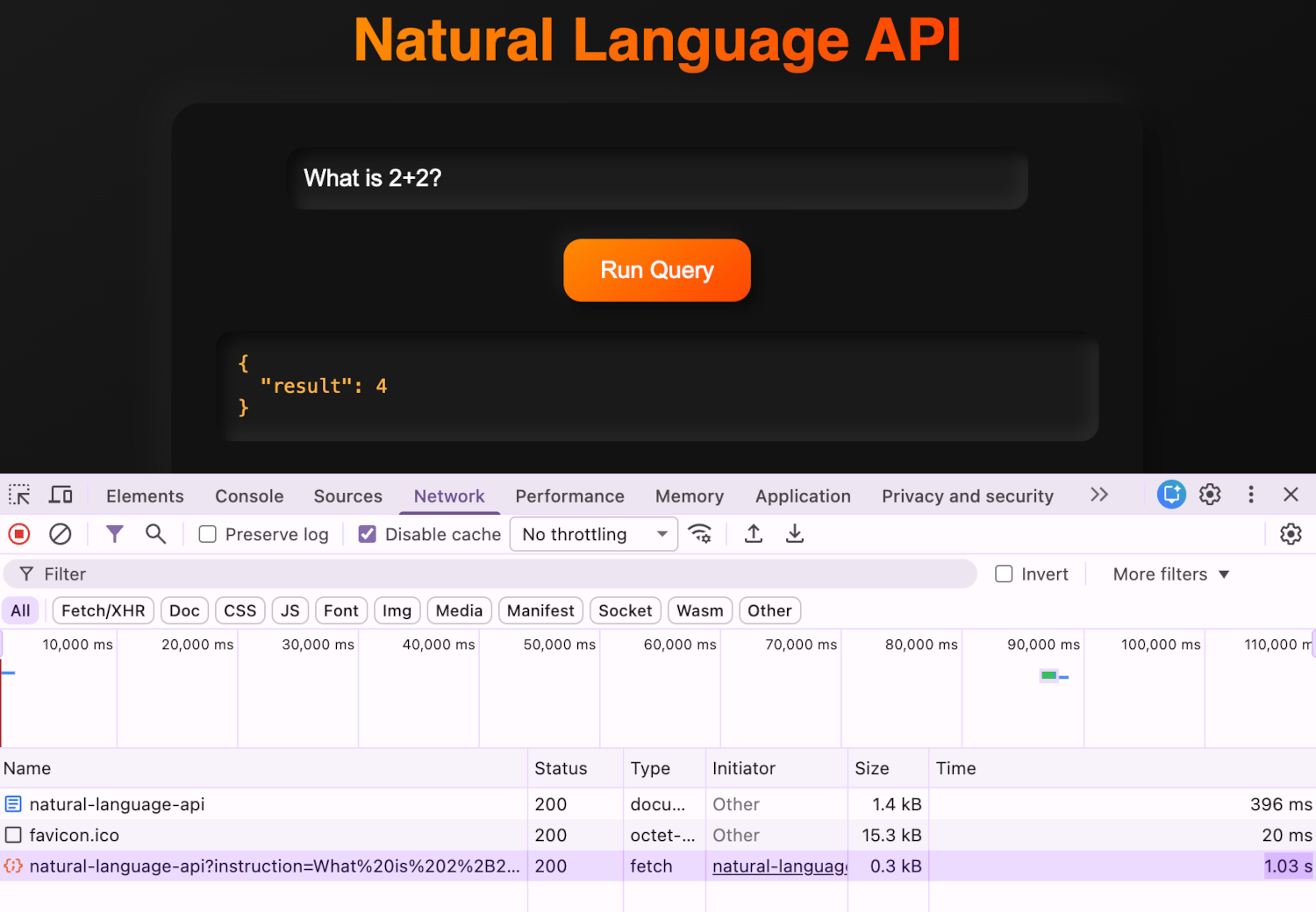
The above screenshot of course shows our Natural Language API being capable of answering the question; "What is 2+2?" in 1.03 seconds!
This means that Hyperlambda is literally the only programming language on earth that can pull something like this through, in real time, without introducing security threats of such magnitude, it'll make Shai-Hulud resemble a maggot in comparison. For the record, in case you wonder, we were never infected ...
If we imagine an average response time of 2 minutes using Python and Docker, we've got an improvement of roughly 120 times with Hyperlambda on execution speed - And I need to emphasise, this is running on "fairy dust" in comparison to the machines you'd need to dynamically spawn off containers - Implying in electricity costs and hardware costs, something equivalent written for Python would probably literally cost 1,000,000 as much in electricity and hardware.
And that's before we even consider the fact that any Python solutions down this road, would be useless due to the fact that they'd need 2 minutes to execute, instead of one second!
So anything not created in Hyperlambda would basically ...
- Be 1,000,000 times more expensive
- Require 120 times as much time to execute such functions instead of 1 second (rendering them practically uselesss)
- Use about 1,000,000 more electricity for each invocation
- Etc, etc, etc ...
Natural Language Logic Protocol
You see, Hyperlambda is the perfect vehicle for something I refer to as "natural language-based 'logos' protocol", allowing in theory web servers to connect to each other using natural language such as the above illustrations, to communicate with each other, in a way that's first of all both transparently understood by us - And secondly, and more importantly I guess, using the same "interfaces" as we're using. I'm 100% certain about that there's a couple of "alignment points" upstairs there somewhere, if you're a doomer BTW ... 😉
However, it's not about natural language, it's about logic and collaboration. If I connect my server to another Magic server for instance, then I can initiate collaboration with the other server - At which point I could simply ask the other server; "Return all slots I can invoke?" Which will return something such as this ...
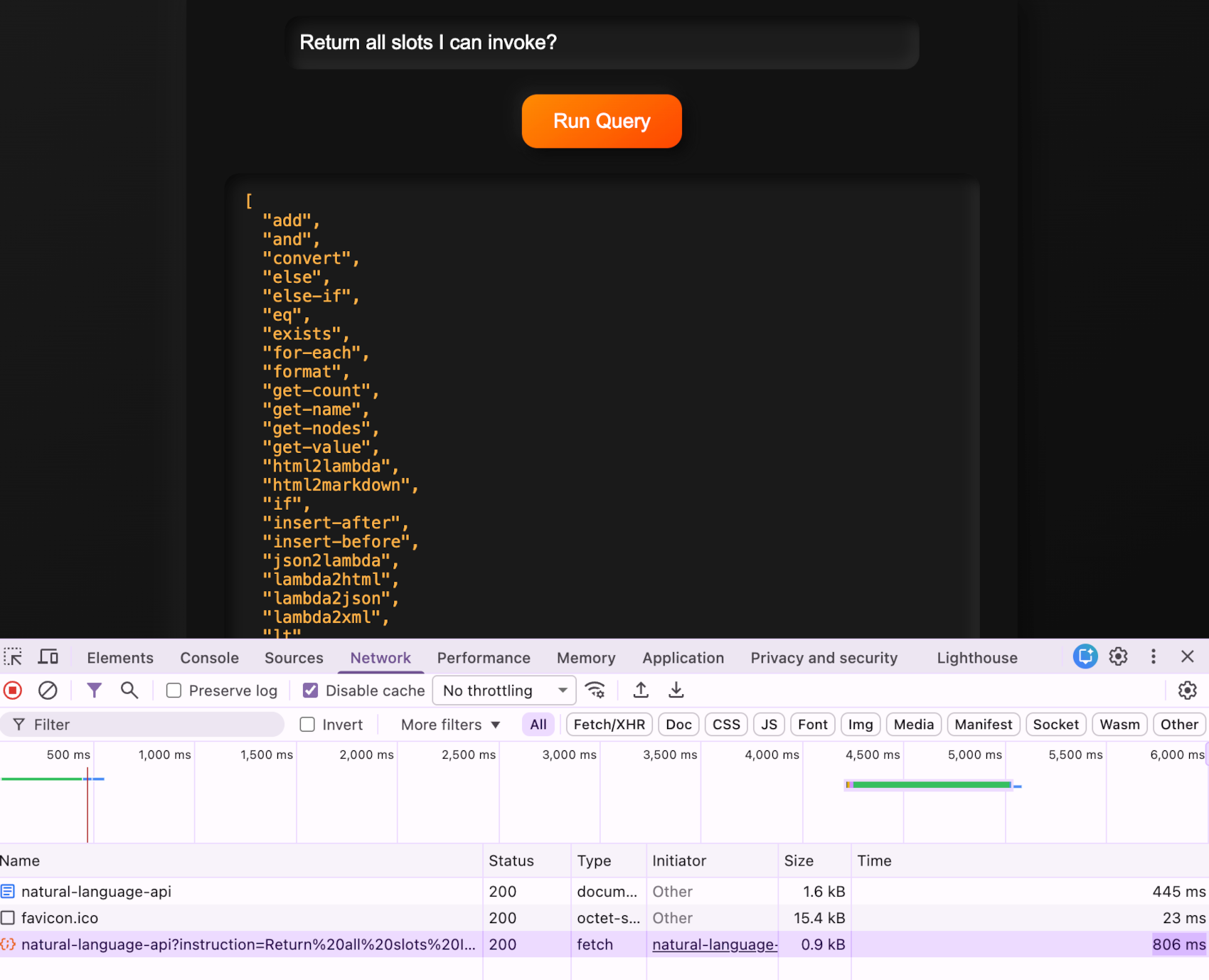
... which again of course is the legal sub-set of slots that you can execute on the server you're asking the question to. Which of course is only possible in a meta programming language. This allows servers to mutually "handshake" each other, which results in that they "discover" what Hyperlambda vocabulary they can execute on the other machine(s), for then to dynamically generate natural language that somehow results in code solving the AI's specific problem at hand, whatever that is.
And more importantly ...
Evolutionary-Based AI Agents
The above header is such an obvious use case it's impossible to argue against. To understand why, realise that this allows me to deliver AI agents, where the agent in its pristine and original state knows "nothing", except one thing; How to dynamically generate Hyperlambda code from natural language and save as "tools" in a RAG database, and/or having the ability to modify its own system instruction.
And the thing would just offer to create and save tools for the user automatically, and such "naturally evolve" its abilities, learn new things, according to what requirements the end user has at any one particular point in time ...
This again allows the AI agent to "evolve" as it is interacting with its "owner", and develop tools according to whatever needs and requirements the user has, instead of "qualified guesswork", which is kind of like how the vertical works now. Watch the following video by yours truly to understand the idea here, and its opportunities.



