Performance - LangChain versus Hyperlambda

This week I've been measuring performance of Flask versus Hyperlambda and Fast API versus Hyperlambda, and basically it's a slaughter house. However, the problem isn't Flask or Fast API, the problem is Python. Which implies LangChain too suffers from the same performance issues, and the performance isn't even possible to fix using Python.
Python was never intended to create backend APIs, it was created to be a simple "bash script replacement". This made it incredibly easy to write code in. Later others added Django, Flask, and Fast API to it as "additional plugins, libraries, and frameworks" to simplify creation of web APIs. However, creating a performing web API in Python isn't even possible in theory! Python was simply never built for that purpose.
If you start complaining about Python's performance on Reddit, the standard answer is; "Python is great for MVPs". OK, maybe it is, but why is it running 70 to 90 percent of all production-grade AI agents then today?
Hyperlambda again was built from the get go to be an extremely high performing API programming language, and even arguably allows you to port your Python APIs in seconds using our CRUD generator.
LangChain's Performance
Hyperlambda is somewhere between 15 to 25 times faster than LangChain, simply because LangChain inherits its bad performance from Python. There is absolutely nothing you can do to optimise it either. Google tried for 20 years, but fired the whole team a couple of months ago. Hence, LangChain's developers can create the best Python code you've ever seen, deliver a "bajillion" times as high quality code as I do with Hyperlambda, and still not have more than 5% of Hyperlambda's performance!
LangChain is broken because they chose the wrong programming language ...
This means that if you build an AI agent in LangChain that can deal with some 20 concurrent users, you could deal with 400 users if you had built it in Hyperlambda.
Python versus Hyperlambda, complexity yield
LLM tokens is actually a very good metric to measure "complexity yield". Complexity yield again, just measures your technical debt, and the more complex solutions you've got, the more "cognitive energy" is required to maintain your solution. On average, Hyperlambda is 6.27 times better than Python on token count.
This implies that if you needed $10,000 per month to maintain a Hyperlambda solution, for things such as salary, etc - You'd need $62,700 to maintain the equivalent Python solution, and your Python solution would only be able to deal with 5% as many concurrent users, and be roughly 20 times as slow.
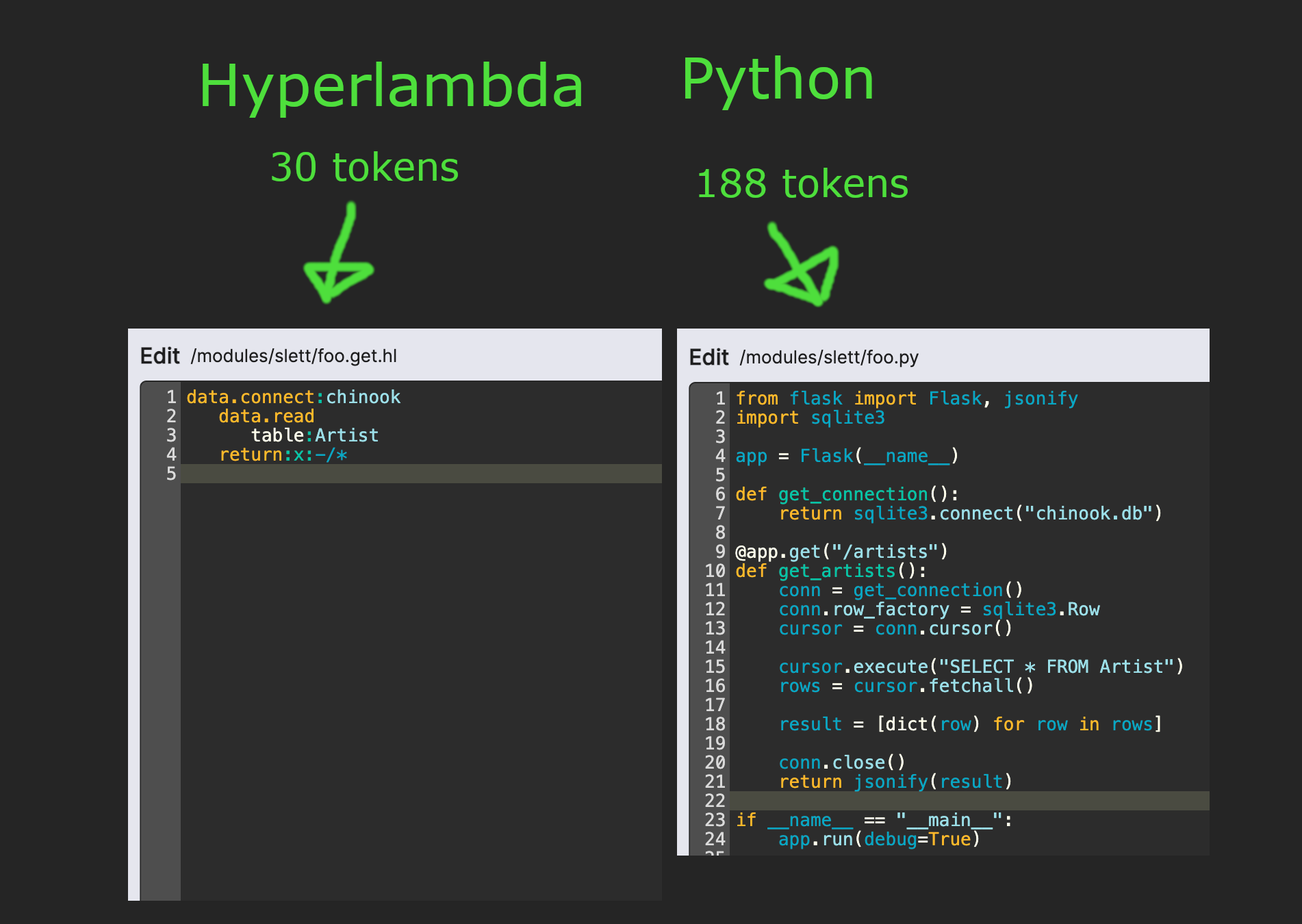
Combining these two facts, makes it painfully obvious that we shouldn't use Python for anything AI. Literally, if you start out building your next AI agent with Python, you're starting on a "broken foundation". The problem is you won't notice it before it's too late, and you've got 400 concurrent users, hammering your server at the same time ...
Initially it works, with 2 or 3 users. When you add 10 or 50 users to it, it starts failing ...
Of course for a SaaS company, typically selling multi-tenant systems, this typically implies you'll need 20 times as many servers, and complicating load balancing, to the same solution you could run from a single server if it was Hyperlambda. A single Hyperlambda server typically outperforms an entire Kubernetes cluster of 20+ Python servers for these reasons ...
CRUD generator
We've got a pretty kick ass CRUD generator. Basically, point it at your database, click a button, and 5 seconds later you've got CRUD HTTP endpoints wrapping all your database tables. Our CRUD generator was explicitly built to ease the porting of Python apps to Hyperlambda, giving you a nice and easy upgrade path. If all you're doing with your AI agent is CRUD, you can "port it" to Hyperlambda by literally clicking a button ...
However, once you combine it with our ability to generate working API code using natural language and AI, you end up at a sweet spot where you can basically move your entire LangChain solution into Hyperlambda in a couple of days - Depending upon just how complex your existing solution is.
Wrapping up
There is no way to say this politely, but LangChain is basically fundamentally broken. Yes, you can build something that works with 5 to 10 concurrent users, but once you start hitting 50+ users, LangChain basically breaks down, and you've got to start "baby sitting" your servers to make sure everything is working.
According to ChatGPT roughly 70 to 90 percent of all AI agents are currently being built in Python. I must assume a lot of them are built with LangChain, considering it's got 120K stars on their GitHub project page. This implies that 70 to 90 percent of AI agent projects will fail, simply because they used the wrong tool to create the agent!
Paradoxically, this number is almost 100% match to failure ratios of AI agents in general. According to McKinsey 95% of AI agent projects fails. My response? Well, when you start out setting yourselves up for failing, what did you expect ...?
LangChain is "broken by design", and it cannot be fixed, because they created it in Python ...
So the comparison between Magic Cloud and Hyperlambda, versus Python and LangChain becomes ...
- LangChain, broken by design. NEVER use it!
- Hyperlambda, 20x faster than LangChain ...
Psst, Magic Cloud and Hyperlambda is open source, and I'm (obviously) biased having create Magic Cloud and Hyperlambda - But feel free to reproduce my performance tests if you doubt me.
- Hyperlambda is 17 times faster than Python with Flask
- Hyperlambda is 20 times faster than Fast API and Python
And the fact that I didn't actually measure LangChain is irrelevant, because the failure from Fast API and Flask originates from Python, which is something they both share with LangChain. A good rule of thumb is as follows;
Never, ever, ever, ever accept that your developer uses LangChain (or Python) to create your next AI agent, it's simply not powerful enough for more than max 50 concurrent users ...



